
Unpredictable Patterns #151: When we become guests in language
The future of language, minority strategies and the cross-over point

Dear reader,
Welcome to the first newsletter of the year. I took January to think and read, and really enjoyed coming back to the writing of the newsletter. I will now aim to publish regularly, but with a gentler cadence than once a week - I am working on a few other things as well. On February 26th, David Skelton and I are publishing our book The Future Habit (do pre-order, if you are interested, it really helps us) and I am thinking about new writing projects this year. My ambition is to write about things that I think are undervalued, and try to find subjects that can be both worth debating (so comment please!) and revisiting in other formats. We start this week with a note on the future of language, and how we can prepare for becoming guests in the house of Being…
Participating in language
“Therefore this statement holds true: Language is the house of Being.” - Martin Heidegger“The limits of my language mean the limits of my world.” - Ludwig WittgensteinLanguage has a good claim on being what makes us human and it holds, rightly, almost endless fascination for us as a phenomenon. We study it technically in linguistics, we explore it in poetry and we use it in philosophy as a means to find our way. We live in language - and it is, as Heidegger notes - the house of Being; it is in language we experience the world, think, feel and learn. Up until this point in time we have also been, relatively alone in language. That may be changing as large language models produce increasing amounts of language on their own, some for us and some for each-other.

One way to think about language is to say that it is the sum total of all recorded words - whether in writing, spoken or otherwise fixed in some way. This total corpus can then be examined to understand how language changes over time. We can study the emergence of sociolects and fashions, the demise of individual languages as well as the birth of new ones, dialects and shifts in emotive values, meaning and depth. By applying different metrics and measures we can try to chart the evolution of this corpus over time, to perhaps get a sense of what the future of language looks like.
One such metric could be the amount of recorded language that is produced by human beings. Up until the 20th century that was a simple metric - all of language was produced by us, but as we started to explore new technologies we also opened up the possibility for machines to produce language as well, or so it seems. Here we need to be careful - what do we mean when we try to make a distinction between language produced by us and language produced in other ways?
Surely, words printed by a typewriter are still produced by us, even if the machine is an intermediary? And what are LLMs but extraordinarily advanced typewriters where the input and output are not directly related in the way pressing a key on a keyboard is, but still bound by necessity - albeit a statistical one? Each prompt is but a pressed key, each response a statistically produced response equal to that of the ink on the sheet of paper in the typewriter? All language is still produced by us, surely? What has changed is merely the means of production and the complexity of that production? What is the real difference between AI and autocorrect, after all?
I am not sure. I would like to challenge that position, by suggesting that at some point the complexity of the production means that we encounter a difference in kind here: language is no longer produced by us, but by this new Other. It truly, in a fundamental sense, speaks and participates in language.
One reason I think this is a defensible position is that we can already see language change.
A growing body of research is now documenting how LLMs are reshaping human language, both in writing and in speech. Tom S. Juzek and Zina B. Ward analyzed scientific abstracts from 2020 and 2024, identifying 21 "focal words" (including "delve," "intricate," and "underscore") whose sharp increase in frequency is attributable to LLM usage rather than natural linguistic drift, with evidence suggesting that reinforcement learning from human feedback (RLHF) may be driving this lexical overrepresentation. Mingmeng Geng and Roberto Trotta examined over 30,000 papers and 1,000 oral presentations from machine learning conferences, finding that LLM-characteristic words like "significant" have increased in both written abstracts and spoken talks—the first study to track this spillover within the same population. More striking still, Hiromu Yakura and colleagues transcribed and analyzed 280,000 YouTube videos from over 20,000 academic institution channels, documenting a statistically significant shift toward ChatGPT-distinctive vocabulary in human spoken language following the model's release—the first empirical evidence that people are unconsciously imitating LLM patterns even when speaking aloud. Zhivar Sourati, Alireza S. Ziabari, and Morteza Dehghani synthesize these and related findings to argue for a broader "homogenizing effect": as everyone increasingly relies on the same models across contexts, LLMs create a feedback loop that standardizes not just vocabulary but reasoning strategies.1 A homogenization that starts in language.2

Being a speaker, we could argue, authentically producing and participating in language, is being able to change language, and if models are capable of this, then they have become something more than mere statistical parrots.3
We could also imagine other criteria to help decide if there is real participation in language. One such criteria could be engagement and empathy. When we enter into dialogue with someone, they engage us, wrap us into a shared production of meaning, often with emotional as well as intellectual reactions to the dialogue. This, of course, is a much harder criterion to get right - but you could imagine a simple Turing test-like set up where you have someone enter into dialogue with a human and a machine without knowing which is which and then ranking the empathy experienced in the exchange.
There are some studies that come close to this, often in healthcare settings. A study published in npj Digital Medicine examined how cancer patients, rather than clinician evaluators, perceive empathy in AI chatbot versus physician responses. Researchers surveyed 45 oncology patients at a tertiary cancer centre, presenting them with responses to 100 cancer-related questions originally posted on Reddit's r/AskDocs. Each participant rated the empathy of blinded responses from physicians and three versions of Claude (V1, V2, and V2 with chain-of-thought prompting) on a 5-point scale. All chatbot versions significantly outperformed physicians: Claude V2 with chain-of-thought prompting scored highest (mean 4.11, 95% CI 3.99–4.22), followed by Claude V2 (mean 3.72, 95% CI 3.62–3.81) and Claude V1 (mean 3.35, 95% CI 3.23–3.48), while physician responses averaged just 2.01 (95% CI 1.88–2.13; all comparisons p<.001).
The study was terminated early after interim analysis revealed significant effect sizes.
We probably need to think more about what criteria we would like to apply to assess real participation in language, but these two tests at least provide us with a starting point, and, I would argue, both indicate that LLMs are participating in language.
That said, I can imagine a robust challenge to this position that tries to distinguish the production of language from the production of meaning. There may be more language, we could say, but it is only the human mind that can produce meaning - and meaning is what really determines participation in language. A machine cannot produce meaning, and the ability to produce signs is useless without the ability to perform semiosis. My tentative reply to this would be pragmatist: meaning is use, and machines use language and we use the language produced by the machine. But I think there is a deeper debate to be had here, and I welcome it.
The corpus
Let’s assume for the sake of argument that LLMs are indeed participating in language, and that we can have a look at that metric we proposed: how much of language we produce, and how much is produced by the machine.4 Where are we then? Are we close to the point where a majority of language is produced not by us, but by the machine? At what point do we become a minority in language?
Let’s try a quick and dirty Fermi estimate. In February 2024, Sam Altman posted the following claim: OpenAI was generating 100 billion words per day, while all humans on Earth produce roughly 100 trillion. That put AI at 0.1% of human output—a rounding error. But how would we actually verify either number, and what’s happened since? Start with humans. Take the 8.2 billion people on Earth, assume 90% are of speaking age and ability, and multiply by the ~12,600 words per day that recent research suggests we speak on average (the famous 16,000 figure from 2007 has been revised downward as texting substitutes for talking). That gives us about 93 trillion words from speech alone. Add the 200 billion legitimate emails sent daily at roughly 75 words each (16 trillion), plus messaging apps, social media, and professional writing, and you land at approximately 110 trillion words per day. Altman’s estimate seems to hold up at least when it comes to order of magnitude.
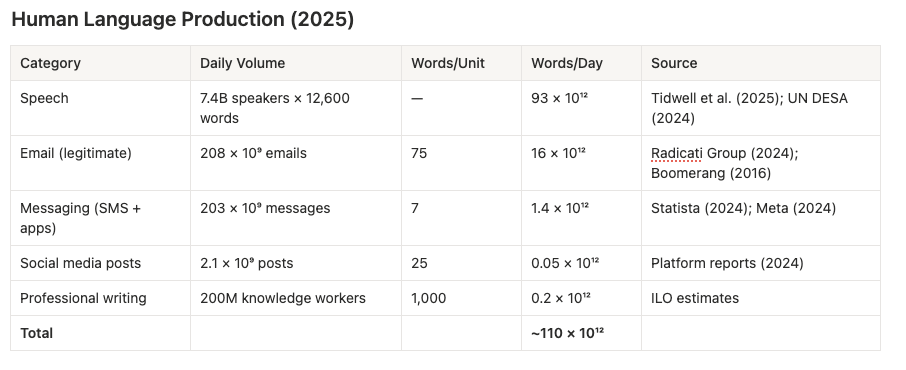
Now for AI—and here’s where it gets treacherous. The numbers being reported are enormous: Google processes 1.3 quadrillion tokens monthly, OpenAI’s API handles 8.6 trillion tokens daily, Microsoft Azure processed 100 trillion tokens last quarter. But these figures measure throughput, not output. When an AI summarises a document, it might read 10,000 tokens to produce 100. When it answers a question using retrieval-augmented generation, the ratio can be 50:1 or higher.
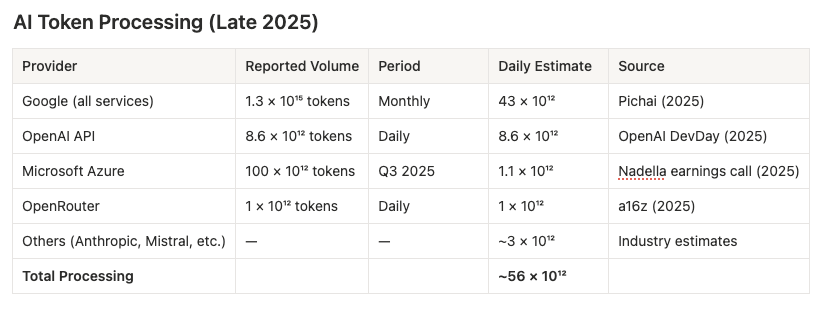
Across typical use cases—chatbots, code generation, document analysis, agentic loops—a weighted estimate suggests roughly 15% of processed tokens are actually generated output. Apply that correction to the ~56 trillion tokens processed daily across major providers, convert to words (about 0.75 words per token), and AI’s generative output falls to approximately 6 trillion words per day. That’s not 0.1% of human output anymore—it’s about 5.5%. AI has grown perhaps 60-fold in under two years, but it’s still producing roughly one-eighteenth of what humans produce.
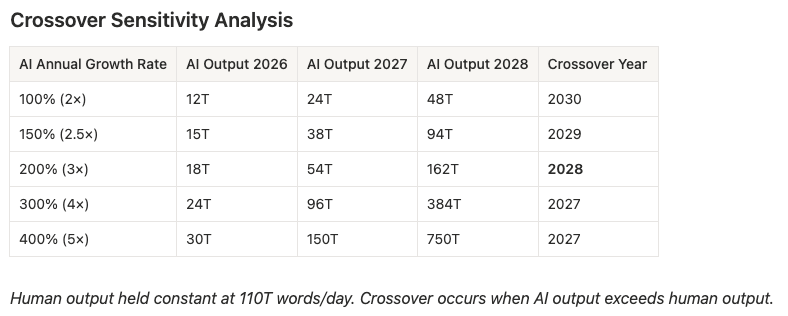
The crossover calculation is then rather straightforward, if very sensitive to assumptions. If AI output continues growing at 200% annually (conservative relative to the 2024-2025 trajectory, but acknowledging that growth slows as bases expand) while human output remains roughly flat, the curves intersect around mid-2028. Slow AI growth to 100% annually and you push crossover to 2030; accelerate it to 300% and you pull it forward to 2027. But the real wildcard is agentic AI—systems that communicate with other systems in loops no human ever reads. When autonomous agents begin debugging code, negotiating API calls, and coordinating workflows, they’ll generate vast quantities of “dark matter” language that won’t show up in consumer-facing form, but still will silently become a part of our corpus.5
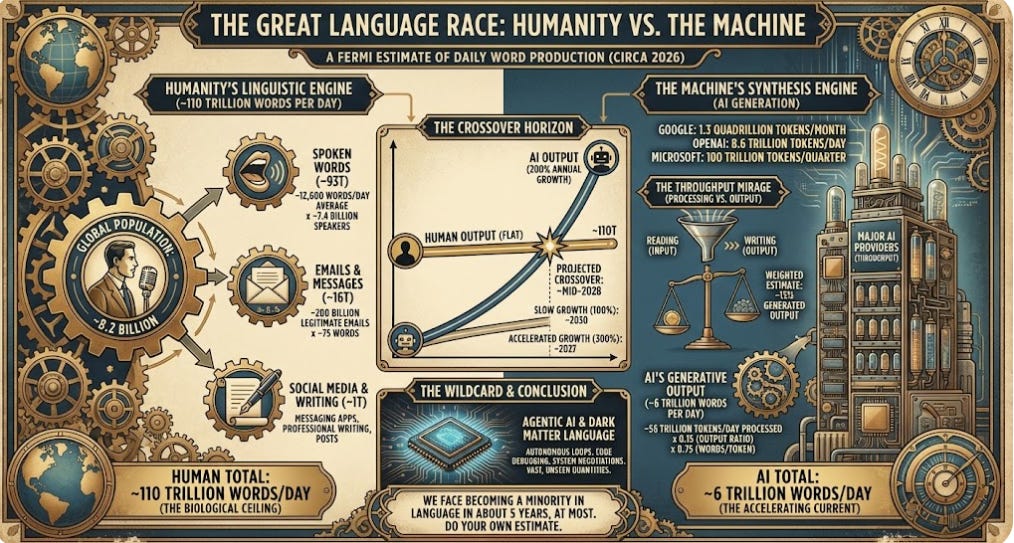
This is just a Fermi estimate, a structured guess, of course. You should do your own, and share - I suspect that it can look very different, but not that different in terms of the horizon, and we face becoming a minority in language in about 5 years, at most.
Minority strategies
It is 2030, and biological production of language has been dwarfed by computational production. Humanity has become a guest in language and our words, concepts and the limits of our world are now set by computational speakers. What do we do? Do we let this happen? Do we even try to stop it?
Resistance is an option, of course. We could stop using language models, or demand that everything they write expires so that they do not make a constant mark in our corpus. LLM-produced language could be regulated and we could force ephemerality on AI: no text produced by AI gets to last longer than two years. But given how many people today write, partly or wholly, with these models we would need very good provenance technologies to do this, and we would risk losing quite some human output as well in such a scheme.
Another form of resistance could take the form of labelling and marking up human content as human, and ensure that it is not contaminated by LLM-language.6 Designating certain areas - theater, poetry, cinema, games - as human language domains and safe-guarding them would allow for keeping some areas of language under human dominance. It seems likely that such areas would quickly be encroached upon, and how do you ensure that the poets does not get infected by computational language? Do you isolate them all on an island with no computers and no access to our shared language? What then happens with poetry as a shared experience? The very function poetry has means that it needs to subvert ordinary language, and so understand and command it. Better then to pay the poets handsomely for guerilla warfare in language, and to read poetry as a means to inoculate ourselves against machine discourse.
In this world human language becomes artisanal, but still dependent on and connected to a language in which we are now guests. The idea that you could compartementalize linguistic spaces and protect them is optimistic at best.
There is also acceptance. We used to be the only ones that carried language on our shoulders, now we can shared the burden. What we need to do is not resist the machine, but teach it. If it is to participate in language, let’s make it a better speaker than we are, one more sensitive to truth, adverse to lies and with a deep set respect and alertness for the tendency we have to craft self-deception through our choice of words.
We need to be careful here, and not succumb to the dream of a better, purer language curated by a wiser machine - but there is something here, the possibility of expanding the limits of our world through judicious exploration of the linguistic adjacent possible. So much of our world, our institutions, breaks down when language becomes brittle and our divisions enshrined in the way we use words. Our need for a shibboleth to distinguish us from them is pervasive and destructive. A new language, carefully curated and evolved might also mean a new world.
And then again we might just never notice, just like we today live in language and rarely pay attention to its wonder.
Thanks for reading,
Nicklas
A phenomenon risking, they note, marginalizing alternative voices and flattening the cognitive diversity that drives collective intelligence and adaptability.
See Geng, M. and Trotta, R. (2024) ‘The impact of large language models in academia: from writing to speaking’, Findings of the Association for Computational Linguistics: ACL 2025. Available at: https://aclanthology.org/2025.findings-acl.987.pdf, Juzek, T.S. and Ward, Z.B. (2024) ‘Why does ChatGPT “delve” so much? Exploring the sources of lexical overrepresentation in large language models’, Proceedings of the 31st International Conference on Computational Linguistics (COLING 2025), pp. 5765–5780. Available at: https://arxiv.org/abs/2412.11385, Sourati, Z., Ziabari, A.S. and Dehghani, M. (2025) ‘The homogenizing effect of large language models on human expression and thought’, arXiv preprint arXiv:2508.01491. Available at: https://arxiv.org/abs/2508.01491, and Yakura, H., Lopez-Lopez, E., Brinkmann, L., Serna, I., Gupta, P. and Rahwan, I. (2024) ‘Empirical evidence of large language model’s influence on human spoken communication’, arXiv preprint arXiv:2409.01754. Available at: https://arxiv.org/abs/2409.01754
This does not have, as far as I can see, any implications for the discussion of artificial consciousness other than for those who hold the view that participation in language is the only objective criteria we have for the ascribing of consciousness to something.
I use the term “machine” here just to contrast against humans - it is not meant in a threatening or derogatory way, just as a way to distinguish biological from computational language users.
Why would it matter if agents talk to each other for us? We still live in our house of language and they can live in theirs? Well, the cross-over vectors still exist, and new models trained will certainly also be trained on this dark matter, allowing it to then influence us as well.
See eg https://notbyai.fyi/
I wonder if you detect the AI influence in spoken English. I hear *about* it all the time--the "delve" etc. But I've not perceived any change. I might add that the words AI is purportedly elevating are often perfectly good! If people learn to say "delve" and "underscore" and "intricate" more, that doesn't seem too bad. Far worse is the jargon that still pervades human speech. Maybe a benevolent AI designer will someday prune a few of the most annoying words, and help people become more eloquent in our coming linguistic cohabitation!
Thanks for this!
Three thoughts/questions:
Doesn't the issue go beyond LLM-characteristic vocabulary? LLM-specific syntax is creeping in to spoken and written "human-generated" texts: "not... but....", "less about.... more about....", lists of three, overly diplomatic, etc.
Is this primarily an Anglosphere issue? My sense is that the LLM text explosion isn't as marked in other "smaller" languages? And what's the situation in Chinese?
"Biological language" is a bit, well, anthropocentric, no? What if we include all the meaning-making and communication that takes place in the more-than-human world (animals, trees, etc.)? But perhaps it's wrong to call that language in the first place - you know much more about semiotics than I do.